We maken meer en meer gebruik van big data ten behoeve van statistisch onderzoek. Maar welke technieken en methoden zijn voorhanden om big data te verwerken? En net zo belangrijk: hoe kunnen we fouten opsporen in de betreffende data? Om de bewustwording rondom big data en statistiek te vergroten, bieden de Open Universiteit, het CBS en Zuyd Hogeschool vanaf 26 oktober 2020 een twaalf weken durende online cursus aan. Deze cursus heeft een gecertificeerde variant (tegen betaling) en een gratis variant.
Als organisaties en individuen ontwikkelen en delen we via internet grote hoeveelheden gegevens. Daarbij hechten we steeds meer waarde aan ‘big data’. Big data worden daarom ook wel eens ‘de nieuwe olie’ genoemd. Heel veel verschillende organisaties maken al gebruik van big data, door bijvoorbeeld gericht advertenties op basis van online surfgedrag aan te bieden.
Bewustwording
Door gebruik te maken van big data kan onderzoek beter en sneller worden uitgevoerd. Big data worden ook in toenemende mate gebruikt voor statistisch onderzoek, op basis waarvan overheden en organisaties belangrijke beslissingen nemen. Zo gebruikt het CBS bijvoorbeeld big data bij het bepalen van de inflatie en de verschuiving van het gebruik van fossiele brandstoffen naar schone energiebronnen als zonnestroom. Mensen uit diverse disciplines en organisaties moeten in staat zijn grote hoeveelheden statistische informatie te interpreteren of onderzoek zelf uit te voeren. Daarvoor hebben ze kennis nodig van methoden en technieken om big data te verwerken, en de kwaliteit van de verschillende bronnen te kunnen beoordelen. Dit begint met het creëren van bewustwording ten aanzien van het gebruik van big data voor statistisch onderzoek, inclusief technieken voor het verzamelen en verwerken van gegevens.
Niet feilloos
Deze online cursus over big data en statistiek, mede mogelijk gemaakt door de CBS Academy en het bijzonder lectoraat Statistiek en Data Science (onderdeel van het lectoraat Future-proof Financial) van Zuyd Hogeschool, richt zich dan ook vooral op het creëren van dit bewustzijn. De cursus met een inleidend karakter is bedoeld voor alle mensen die te maken krijgen met statistisch onderzoek en big data. Als deelnemer leer je dat big data niet feilloos zijn en weet je waar je straks op moet letten om te achterhalen of data fouten bevatten. Verder leer je de kwaliteit van bronnen te bepalen aan de hand van indicatoren, en de voor- en nadelen van verschillende typen data bij statistisch onderzoek te benoemen. Je werkt niet daadwerkelijk met data en databestanden.
Opzet cursus
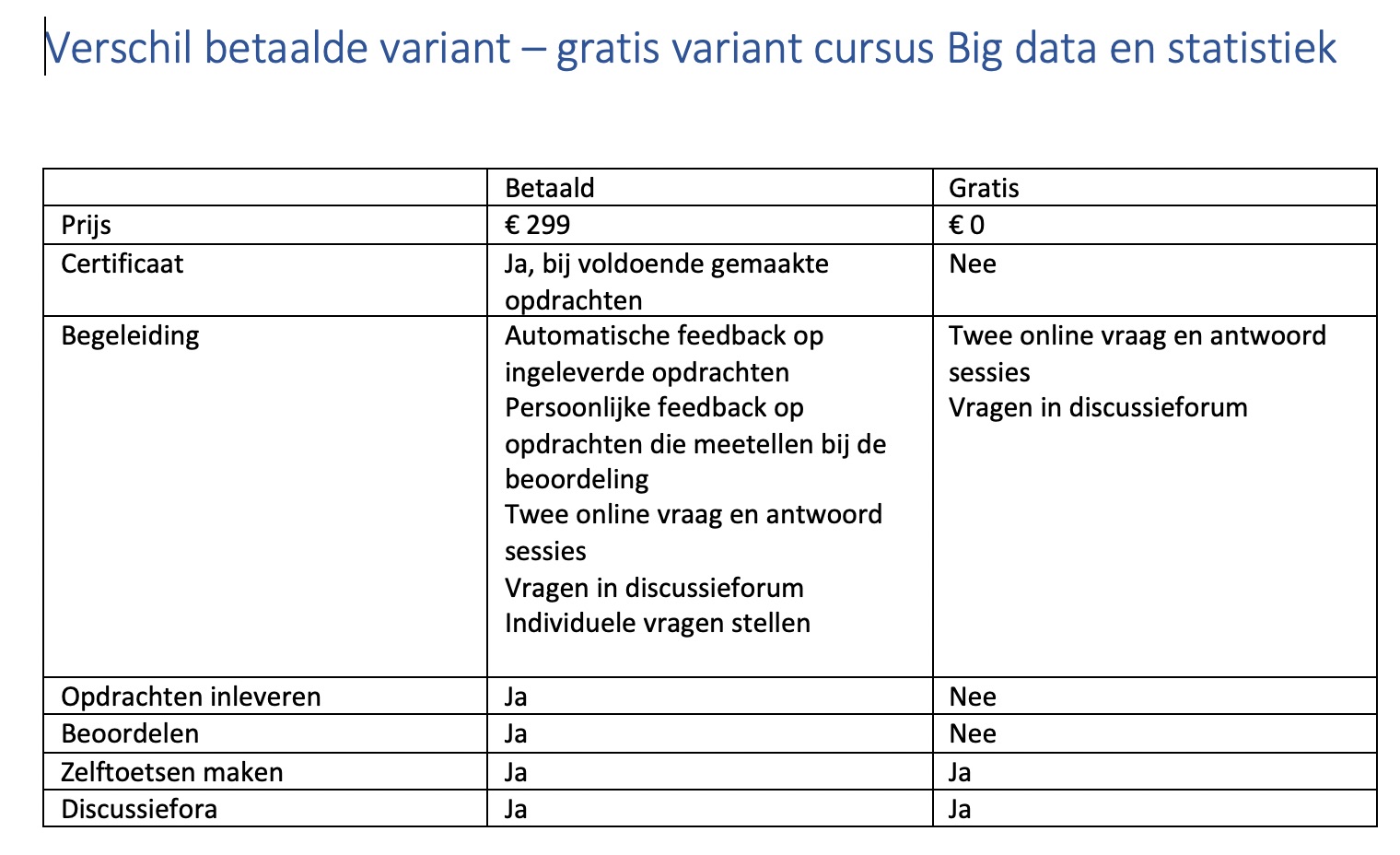
De cursus duurt twaalf weken, en bestaat uit zes thema’s. Binnen elk thema ben je als deelnemer ongeveer 4 tot 5 uur bezig met het bestuderen van instructies, voorbeelden en het maken van opdrachten. De cursus is vrij toegankelijk, maar inschrijven is verplicht. Daarnaast is het mogelijk om tegen een betaling van € 299,- een certificaat van de Open Universiteit te ontvangen. Voorwaarde hierbij is wel dat je de opdrachten voldoende hebt gemaakt. Heb je betaald, dan krijg je ook een reactie op je gemaakte opdrachten.
Tweede editie
Deze editie is de tweede editie van deze cursus. Verleden jaar telde deze cursus 875 inschrijvingen. 334 personen hebben deelgenomen aan de gecertificeerde versie. Op basis van de evaluatie is de cursus bijgesteld.
Ik ben betrokken bij de ontwikkeling en uitvoering van dit programma.
This content is published under the Attribution 3.0 Unported license.
Geef een reactie